|
Optimizations in a multicore pipeline
November 6, 2014
This is a story that happened during the development of
Video Enhancer a few minor versions ago.
It is a video processing application that, when doing its work, shows two
images: "before" and "after", i.e. part of original video frame and the same part
after processing.
It uses DirectShow and has a graph where vertices (called filters) are things like
file reader, audio/video streams splitter, decoders, encoders, a muxer, a file writer
and a number of processing filters, and the graph edges are data streams.
What usually happens is: a reader reads the source video file, splitter splits it in two
streams (audio and video) and splits them by frames, decoder turns compressed frames
into raw bitmaps, a part of bitmap is drawn on screen (the "before"), then
processing filters turn them into stream of different bitmaps (in this case our
Super Resolution filter increases resolution, making each frame bigger),
then a part of processed frame is displayed on screen (the "after"), encoder
compresses the frame and sends to AVI writer that collects frames from both video and audio streams
and writes to an output AVI file.
Doing it in this order sequentially is not very effective because now we usually have multiple CPU
cores and it would be better to use them all. In order to do it special Parallelizer filters were
added to the filter chain. Such filter receives a frame, puts it into a queue and immediately returns.
In another thread it takes frames from this queue and feeds them to downstream filter. In effect,
as soon as the decoder decompressed a frame and gave it to parallelizer it can immediately start
decoding the next frame, and the just decoded frame will be processed in parallel. Similarly,
as soon as a frame is processed the processing filter can immediately start working on the next frame
and the just processed frame will be encoded and written in parallel, on another core. A pipeline!
At some point I noticed this pipeline didn't work as well on my dual core laptop as on quad core desktop,
so I decided to look closer what happens, when and where any unnecessary delays may be. I added some
logging to different parts of the pipeline and, since in text form they weren't too clear, made a converter
into SVG, gaining some interesting pictures.
Here's how the process looked like on a quad core box with DivX used for encoding. The source was a FLV
file but its splitter and decoder are not shown here because they don't write to my logs, being
third-party components. Time in this picture goes down. Different colors mark different frames.
Decoder gives a frame to the first Sample Grabber which remembers the part of frame we want to display
on screen. It sends the frame to a Parallelizer that puts it into its queue. In another thread
(different threads are shown with different background colors here) the frame is processed by SR
(Super Resolution) filter and sent to another Parellelizer. In yet another thread processed frame from
the Parallelizer queue is given to second Sample Grabber which takes a part of it to display and sends
the frame to an encoder (DivX) which later gives the compressed frame to AVI writer.

DivX doesn't write anything to my logs but since on both sides of it are my filters I know exactly
when it takes a frame and when it gives it out, compressed. In this picture everything goes smoothly:
speed of whole pipeline is limited by its slowest part (here it's SR), this part works 100% of the time
and the other parts work in parallel, taking a rest from time to time waiting for next data portion.
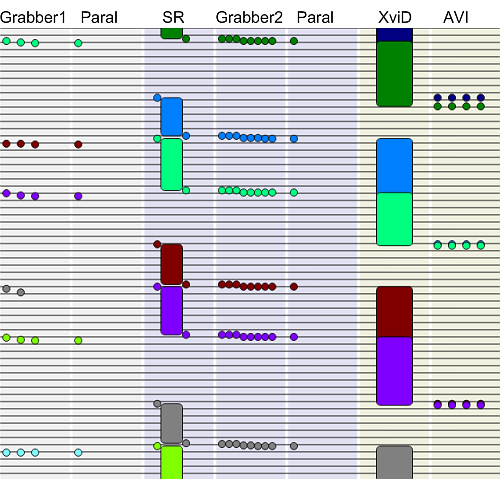
And here's how a similar process looked on my dual core laptop. Source file and processing was the same
but instead of DivX I was using XviD.

None of the pipeline parts work 100% of the time! The processing thread is idle half of the time, waiting
for the encoding-and-writing thread. And that thread is acting weird: sometimes taking a part of bitmap
for displaying happens in a snap and sometimes it takes a lot of time. And while it's
working the encoder does nothing. Also, we can see that the encoder is working weirdly: compressing
some frames takes significant time while some others are compressed in no time at all. Knowing that
we're dealing with MPEG4 where there are B-frames (bidirectional, they are based on both previous and
following frames), it's clear that XviD just remembers every other frame and when receiving the next
frame it compresses both the remembered and the new one. After compressing two frames it outputs one of them
immediately and the second one on the next call, when it will be remembering a new frame. But why does
extracting a part of frame for displaying takes so long sometimes? It is such a simple operation! If we
look closer at the picture here we'll notice: this extraction works super fast (as it should) when the
received frame is still hot, just processed. But if it spends some time in the queue, waiting, then
extracting a part from it takes much longer. It's CPU cache! In first case the frame is still in the cache
and everything is quick. In second case the cache gets filled with other data and to extract part of frame
it needs to be loaded from memory which is much slower, hence the delays.
This lead to first solution: I need to swap places the second Sample Grabber and Parallelizer. Then
extracting a part of frame in the grabber will happen immediately after processing the frame, it won't
leave the cache. And indeed, swapping these two filters made this extraction invariably fast.
The extraction operation became faster without changing a letter in its implementation!
In this picture encoder's times are not really displayed correctly because we know exactly only when a
frame is finished compressing but not when its encoding started. But even so, another problem is
clearly visible here. XviD here is still the slowest part of the pipeline and ideally it should work
100% of the time while other parts of pipeline should sometimes wait until XviD can take another frame.
But here it's not working all the time, part of time it waits until another frame is finished processing.
But why wasn't that frame processed earlier? The processing filter already had this frame and had the time
to process it.
Here's what happened. When some splitter, decoder or other filter wants to create another sample of data
(like a video frame) it requests memory buffer for it from an allocator. This allocator is negotiated
with downstream filter before processing starts (particularly, downstream filter might be a renderer and
provide an allocator that allocates samples directly in video memory). Number of buffers that an allocator
has is strictly limited. If a filter requests a buffer when all of them are taken, this request blocks
until some buffer gets released and becomes free to use. This is how Parallelizer limits its queue length:
by limiting number of buffers in its allocator. Because if we don't limit this length and producing filter
will work faster than consuming one, it will quickly eat all the memory. If we set a limit but make it
rather big, it may take too much RAM for uncompressed video frames. So a long time ago it was decided to
limit Parallelizer's queue by just two samples: one buffer is used by downstream consumer filter, while
the other buffer is getting filled by upstream producing filter in parallel. When the downstream filter
finishes its processing it will release the buffer to allocator and it will become available for the
upstream filter to place one more sample in the queue. This way they work in parallel without consuming
too much memory, but the queue may not have more than one frame waiting. When XviD compresses a frame
and swallows the next one (which was waiting in the queue), remembering it for compressing later,
the queue suddenly becomes empty, and now XviD needs to wait until the upstream processing filter
makes a new processed frame. And before this moment processing filter couldn't do it because both
buffers were taken - one was being compressed, another one waited in the queue.
Hence another solution: taking into account that some codecs behave this way, the queue of frames
for encoder should be made longer. After increasing number of buffers in the second Parallelizer
from 2 to 3 I got the following picture (samples in encoder not depicted, as they overlap because of
increased queue length):

Processing thread started to work fulltime, no more unnecessary waiting! Overall speed increased, although
not too much, because XviD still took too long for some frames but that was out of my control already.
Again, the acceleration happened without changing a bit in the processing parts doing the hard work,
just a change of one constant in the pipeline organization. That was fun!
tags: programming video_enhancer directshow
| 
 RSS
RSS