|
Older posts Optimizations in a multicore pipeline
November 6, 2014
This is a story that happened during the development of
Video Enhancer a few minor versions ago.
It is a video processing application that, when doing its work, shows two
images: "before" and "after", i.e. part of original video frame and the same part
after processing.
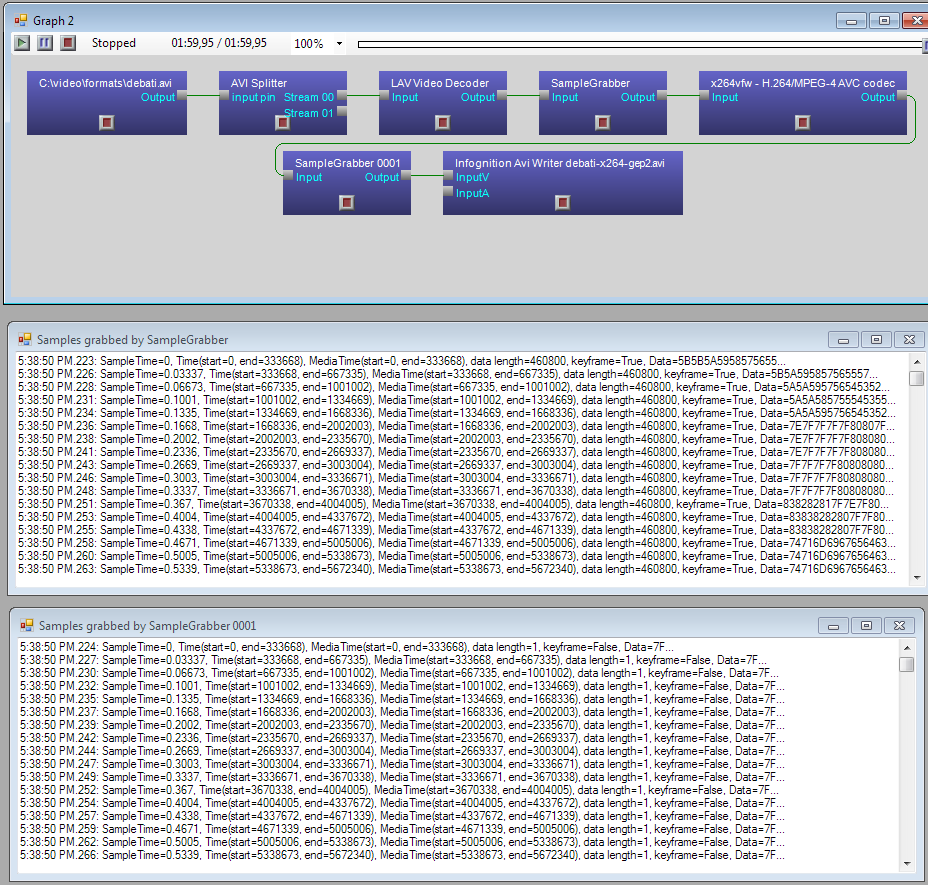
It uses DirectShow and has a graph where vertices (called filters) are things like
file reader, audio/video streams splitter, decoders, encoders, a muxer, a file writer
and a number of processing filters, and the graph edges are data streams.
What usually happens is: a reader reads the source video file, splitter splits it in two
streams (audio and video) and splits them by frames, decoder turns compressed frames
into raw bitmaps, a part of bitmap is drawn on screen (the "before"), then
processing filters turn them into stream of different bitmaps (in this case our
Super Resolution filter increases resolution, making each frame bigger),
then a part of processed frame is displayed on screen (the "after"), encoder
compresses the frame and sends to AVI writer that collects frames from both video and audio streams
and writes to an output AVI file.
Doing it in this order sequentially is not very effective because now we usually have multiple CPU
cores and it would be better to use them all. In order to do it special Parallelizer filters were
added to the filter chain. Such filter receives a frame, puts it into a queue and immediately returns.
In another thread it takes frames from this queue and feeds them to downstream filter. In effect,
as soon as the decoder decompressed a frame and gave it to parallelizer it can immediately start
decoding the next frame, and the just decoded frame will be processed in parallel. Similarly,
as soon as a frame is processed the processing filter can immediately start working on the next frame
and the just processed frame will be encoded and written in parallel, on another core. A pipeline!
At some point I noticed this pipeline didn't work as well on my dual core laptop as on quad core desktop,
so I decided to look closer what happens, when and where any unnecessary delays may be. I added some
logging to different parts of the pipeline and, since in text form they weren't too clear, made a converter
into SVG, gaining some interesting pictures.
Read more...
tags: programming video_enhancer directshow
Special treatment for Deshaker
May 27, 2014
There is a nice filter for VirtualDub (supported by Video Enhancer) called Deshaker
by Gunnar Thalin which can stabilize shaky video. This filter is different from the others
because it works in two passes: first it needs to see the whole video and analyze it
(without producing a meaningful video result yet), and on the second pass it uses collected
data to actually fix the video. The data collected in first pass is stored in a file
which can be specified in filter's options. If you start analyzing another file
previously collected data is erased. This means up to recently Deshaker could not be used
in Video Enhancer's batch mode where you select many files and apply a sequence of filters
to all of them. Because in that filter sequence Deshaker will be configured for either first
or the second pass while each file requires going through both passes one right after another.
To fix this issue we've added in Video Enhancer 1.9.10 special treatment for Deshaker:
when you start processing some video file and your sequence of filters contains Deshaker
then Video Enhancer first makes one pass in preview (without compression and writing to disk)
and then immediately processes the file
again but this time automatically switching Deshaker to second pass. And if you're processing
a bunch of files then this approach applies to each of them: for each file Video Enhancer
will do two passes: quick preview with Deshaker in first pass then actual processing with
Deshaker in second pass.
Of course, if your chain of filters does not contain Deshaker then Video Enhancer works
as usual: just one pass for each file.
tags: video_enhancer
New Super Resolution is ready.
December 13, 2013
This year we explored ways to accelerate and improve our Super Resolution engine,
and overall research, development and testing took much more time than we anticipated
but finally the new engine is available to our users. Today we're releasing it in
a form of VirtualDub plugin. DirectShow filter
is also ready, so after we change Video Enhancer to use the new version there
will be an update for Video Enhancer too. Also, an AviSynth plugin will be released soon.
Our advances in speed allow using it in video players to upsize videos to HD in
real time on modern PCs and laptops.
Generally quality and speed depend on source video and your CPU'a abilities, but here's
an example of changes between our old VirtualDub plugin (1.0) and the new one (2.0) on
a particular file (panasonic4.avi) when upsizing from 960x540 to 1920x1080 on an old
Quad Core 2.33 GHz:
Quality, in dB of Y-PSNR (higher is better):
version old new
fast mode 41.70 42.28
slow mode 42.07 42.73
Time of upsizing 200 frames, in seconds:
version old new_rgb new_yv12
fast mode 19.6 14.4 10.3
slow mode 28.7 19.5 14.0
Version 1.0 worked only in RGB32, so for YUV the speed was about the same as for RGB.
As you may see, the new version's fast mode provides similar quality to old version's
high-quality mode but does it 2-3 times faster depending on color space. And new
version's high-quality mode is still faster than old one's fast mode.
To achieve these speed gains our SR implementation was rewritten from scratch
to work block-wise instead of frame-wise. This way it doesn't need so much memory
to store intermediate results and intermediate data never leaves CPU cache,
avoiding spending so much time on memory loads and stores. Also, we learned to
use SSE2 vector operations better. Unfortunately even in 2013 compilers
still generally suck at vectorizing code, so it requires a lot of manual work.
tags: video_enhancer super_resolution
Status report and plans
September 21, 2013
It's been a while since last Video Enhancer version was released. It's time to
break the silence and reveal some news and plans.
Part of the passed year
was spent on ScreenPressor-related projects for our corporate clients.
But for last several months we've been cooking our new super resolution engine.
It's not on GPU yet but we've found a way to accelerate it on CPU and use
significantly less memory. Actually, reducing memory usage is the key to
acceletarion: nowadays memory access is quite slow compared to computations,
and if you compute everything locally in small chunks that fit into cache
and don't store and read whole frames in memory several times, overall process
gets much faster. For us that meant a complete rewrite of our super resolution
engine, and this is what we did. While remaking the algorithm we had a chance
to rethink many decisions baked into it. Additional CPU cycles freed by
the acceleration could be spent to perform more computations and reach for
higher quality. So we spent several months in research: what motion estimation
method works best for our SR? Shall we work in blocks of size 16, 8 or even 4
pixels wide (the latter meaning just 2x2 blocks of original image)?
Which precision to use for each block size? What is the right way
to combine new frame with accumulated information? For motion estimation we
actually tried it all: using source code generation we generated 160 different
implementations of motion estimation and measured how well they performed
in terms of quality and speed. It turned out usual metrics for selecting
best motion compensation methods in video codecs and other applications do
not give the best results for super resolution: minimizing difference between
compensated and current frame (which works best for compression) doesn't
provide best quality in SR when compensated frame gets fused with input
frame to produce the new upsized image. Then the fusion: is our old method
really good or maybe it can be improved? We used machine learning techniques
to find the best fusion function. And found that actually it depends a lot
on source video: what works best for one video doesn't necessarily work well
for another video. We chose a weighted average for a selected set of HD videos
which means quality of the new SR engine should be higher on some videos
and possibly a bit lower on some other videos, it won't be universally
better.
Now what it all means in terms of releases. The new SR engine is in final
testing stage now and it's a matter of days before it's released in
Video Enhancer 1.9.9 and new version of our Super Resolution plugin for
VirtualDub. Then it will also be released as AviSynth plugin, for the first
time. And then finally it will come as Adobe After Effects (and Premiere Pro,
probably) plugin. Some years ago we offered this Premiere Pro & After Effects
plugin but it hadn't updated for too long and became obsolete, current
versions of these Adobe hosts are 64-bit and cannot run our old 32-bit plugin.
Video Enhancer 1.9.9 will be a free update, and it's going to be the last
1.x version. Next release will be version 2.0 with completely different
user interface, where all effects will be visible instantly. Imagine
"Photoshop for video". Update to 2.0 will be free for those who purchased
Video Enhancer 1.9.6 or later.
We hope everything mentioned above will see the light this year.
VE 1.9.9 in September, plugins in October, VE 2.0 later.
Update: oops, our scheduling sucks as usual. YUV support and thorough
testing took much more time, the releases postponed until December.
tags: video_enhancer super_resolution
Writing AVI files with x264
Seprember 26, 2012
x264 is an excellent video codec implementing H.264 video compression standard.
One source of its ability to greatly compress video is allowing a compressed
frame to refer to several frames not only in the past but also in the future:
refer to frames following the current one. Such frames are called B-frames (bidirectional),
and even previous generation of video codecs, MPEG4 ASP (like XviD), had this feature,
so it's not particularly new. However AVI file format and Video-for-Windows (VfW)
subsystem predate those, and are designed to work strictly sequentially: frames
are compressed and decomressed in strict order one by one, so a frame can only
use some previous frames to refer to. Such frames are called P-frames (predicted).
For this
reason AVI format does not really suit MPEG4 and H.264 video. However with some
tricks (or should I say hacks) it is still possible to write MPEG4 or H.264 stream
to AVI file, and this is what VfW codecs like XviD and x264vfw do. They buffer some
frames and then output compressed frames with some delay, sometimes combining P and B
frames in single chunks. Appropriate decoder knows this trick and restores proper
frame order so everything works fine.
Some time ago we received a complaint from a user of Video Enhancer about x264vfw:
video compressed with this codec to AVI file showed black screen when started playing
and only after jumping forward a few seconds it started to play, but with sound out
of sync. To investigate the issue I made a graph in GraphEditPlus where some video
was compressed with x264vfw and then written to an AVI file. But I also inserted
a Sample Grabber right after the compressor to see what it outputs. Here's what I got:
click to enlarge
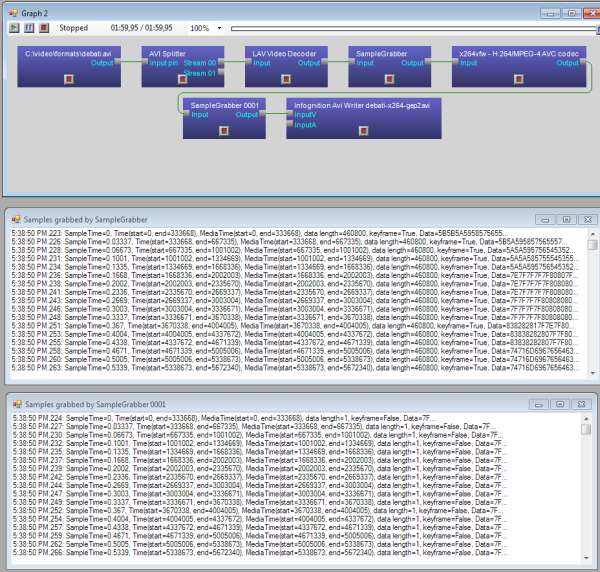
It turned out for some reason x264vfw spitted ~50 empty frames, 1 byte in size each,
all marked as delta (P) frames. After those ~50 frames came first key frame and then
normal P frames of sane sizes followed. Those 50 empty frames which were not started
with a key frame (like it is expected to be in AVI file) created the effect: black
screen when just started playing and audio sync issue. I don't know in what version
of x264vfw this behavior started but it's really problematic for writing AVI files.
Fortunately, the solution is very simple. If you open configuration dialog of
x264vfw you can find "Zero Latency" check box. Check it, as well as "VirtualDub hack"
and then it will work properly: will start sending sane data from the first frame,
and resulting AVI file will play fine.
tags: video_enhancer directshow
Buggy VirtualDub filters
August 16, 2012
The same day I was dealing with VDFilter issue described in previous post
I ran Video Enhancer (which also uses VDFilter), picked a random VirtualDub
plugin and tried to process one file. Suddenly I've got a message telling me
about an exception arised inside that VirtualDub plugin. Most VD plugins have
been here for a while and are known for thair speed, stability and high quality,
so I immediately decided the problem was in VDFilter, our DirectShow wrapper
for those plugins. I started a debug session to find what caused the exception
and luckily the source code for that plugin was available on its web page.
The plugin is called Flip 1.1 (ef_flip.vdf from the big collection of filters by
Emiliano Ferrari). To my surprise however I've found the bug quite fast and it was
not in VDFilter, this time it was in the plugin itself. Source code of the main
routine is pretty short:
void Rotate180 (Pixel32 *dst,Pixel32 *tmp,const int pitch,const int w,const int h,
const FilterFunctions *ff)
{
Pixel32 *a,*b;
int i;
a= dst;
b= dst + (h*pitch);
int alf = h/2;
if (h&1) alf++;
for (int j=0; j<alf; j++)
{
_memcpy (tmp,a,w*sizeof(Pixel32)); // tmp= a;
a+= w;
for (i=0; i<w; i++) *a--= *b++; // a=b
for (i=0; i<w; i++) *b--= *tmp++; // b=tmp
tmp-= w;
a+= pitch;
b-= pitch;
}
if (!(h&1)) // even lines
{
_memcpy (tmp,a,w*sizeof(Pixel32));
a+= w;
for (i=0; i<w; i++) *a--= *tmp++;
}
}
Take a look at the two red lines. h is the image height
and pitch here is equal to the number of Pixel32 values in one row of image, so
h*pitch is the number of pixels in whole image. At first pointer b points
to dst + (h*pitch), i.e. the first byte outside the image buffer! And then
in the loop it's being read and then incremented to point even farther from the end
of the buffer. It didn't cause crashes in VirtualDub because for some reason memory
after the image buffer always belonged to the application, however it did read garbage
there so the first line of "rotated" image should contain garbage after applying this
filter. In case of VDFilter and its use in Video Enhancer one line of memory after the
image buffer not always completely belonged to the program, so for small frames it
worked ok but with a larger frame the b pointer walked too far and caused
a segmentation fault which was caught as an exception and caused our wrapper to
show the message box.
It may be the case that author assumed pitch to be a negative value, however
this assumption doesn't look correct. Here's a quote from VirtualDub Plugin SDK:
"Bitmaps can be stored top-down as well as bottom-up. The pitch value value is positive
if the image is stored bottom-up in memory and negative if the image is stored top-down.
This is only permitted if the filter declares support for flexible formats by returning
FILTERPARAM_SUPPORTS_ALTFORMATS from paramProc; otherwise, the host ensures that the
filter receives a bottom-up orientation with a positive pitch, flipping the bitmap
beforehand if necessary."
Lessons learned: 1) some VirtualDub plugins, even very simple ones, may contain bugs.
2) pointer arithmetic requires a lot of attention to be used correctly.
tags: video_enhancer
YV12 - RGB conversion
September 20, 2010
As mentioned two posts earlier, in version 1.9.4 of
Video Enhancer we added YV12 mode of super
resolution engine. Most video codecs can decode video to several different
uncompressed formats: RGB24, RGB32, YV12, UYVY, YUY2 etc. They differ in
colorspace (red-green-blue or luminosity-color tone1-color tone2)
and data layout. Versions up to 1.9.3 just asked the decoder to provide data
in RGB32 and relied on DirectShow (part of DirectX) and system components to
convert video to RGB32 in case the decoder cannot do it itself. When version
1.9.4 came out it behave differently. It asked the decoder to provide one of
YV12, YUY2, RGB24 and RGB32 formats. If YV12 was given and super resolution
feature was used (either alone or in the beginning of filters sequence)
then YV12 mode of SR was used and then if some VirtualDub filters were
present in the queue, VE relied again on system converters to transform video
from YV12 to RGB32 (in which VD filters work). The same happened when
"Always use RGB32" option was turned on: decoder provided video in one of
abovementioned formats and then a system converter was used.
However it turns out there were
two problems:
- By default there is no system filter for YV12-RGB conversion, so DirectShow
searches for a codec for this conversion. Usually it finds one of old
Video-for-Windows codecs and inserts it in AVI Decompressor wrapper but
some users didn't have a matching codec and VE failed to process a file.
I still don't know which codec exactly was used,
but it had problem number two:
- Conversion from YV12 to RGB was weird, introducing a checkerboard pattern
which was very bad for super resolution. When looking at result of such
conversion one may not notice the problem:

But if we upsize the video it's easy to see the pattern:

So we had to change how VE works with YV12 video and version 1.9.5 was born.
Now it asks the decoder for any of YV12, YUY2, UYVY, RGB24 and RGB32 formats
and if it's YV12 then SR works in fast YV12 mode but if it's anything else
then our own filter converts video to RGB32. The same filter is used for
conversion if after YV12 SR there is some VD filter. No more checkerboard
and no more problems with lack of YV12 codec!

Video quality was the
primary objective for this conversion filter, so it uses proper interpolation
for color tone components (remember that in YV12 color tone resolution is
twice lower in both width and height than in RGB, and in YUY2 and UYVY it's
twice lower in width than RGB but same in height). Bad converter with no
interpolcaion can easily create little blocking artifacts. Here's an example:
Old converter (some codec wrapped in AVI Decompressor):

New built-in converter in Video Enhancer 1.9.5:

(both pictures magnified 3 times).
tags: video_enhancer
Adding translations
September 4, 2010
The recently released version of Video Enhancer
can now speak many languages. The default one is English and translations
to other languages are provided in text files with .lng extension.
User can select a language in Options dialog of VE.
It's very easy to create and edit a translation, just open .lng file from
Video Enhancer folder in Notepad:
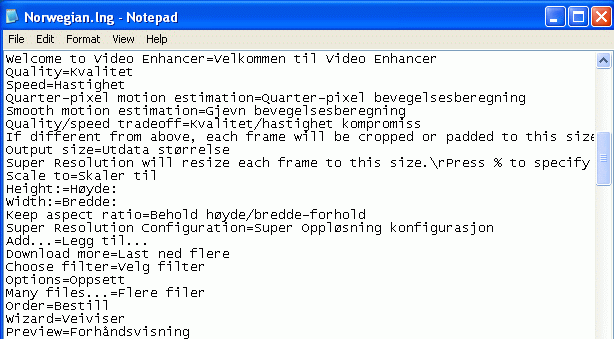
To create a new translation just copy an existing one to a file with
different name but same .lng extension and replace phrases to the right
of '=' sign with phrases of desired language.
Special offer
If you're a native speaker of Japanese, Chinese, Korean or other language
for which there is no translation yet, you can
get Video Enhancer license for free
by spending an hour of your time. Just create one of the following:
- Video Enhancer translation (.lng file for your language)
- OR translation of VE main page text to your
language.
Before starting please email us and introduce yourself. Our address:
tags: video_enhancer
Video Enhancer 1.9.4
September 2, 2010
It's been a while since last released version of
Video Enhancer.
We've accumulated a lot of feature requests from our users and also
came up with our own ideas, so it took quite a lot of time to implement
it all. Now version 1.9.4 is finally out and here's the list changes
worth mentioning:
- YV12 mode for super resolution. All previous versions worked in RGB32
colorspace where each pixel is represented with three numbers: reg, green
and blue. However many modern video codecs work with video in YUV colorspace
where luminosity (lightness) and chrominance (color tone) are stored separately.
YV12 is one of YUV modes. In YV12 chrominance data has twice lower resolution
and for each 4 (2x2) pixels there are 4 distinct luminance values but just
single color tone value (made of 2 bytes), so 6 bytes encode 4 pixels, i.e.
12 bits per pixel, hence the name. Applying super resolution to YV12 video
means much less work to do. Also, RGB super resolution internally calculated
approximate luminance for all pixels - it was used for motion search. In YV12
we already have this data, so that step is just eliminated. Now when VE sees
that source video can be decoded to YV12 and super resolution is the first
(or the only) filter in the sequence, it then applies YV12 variant of SR
which works almost twice faster than RGB version. However VirtualDub filters
work in RGB32, so if SR is applied after some VD filter, RGB variant of SR is
used. In Options window you can disable this behavior and force using RGB in
all situations.
- Scene change detection (less artifacts), mentioned in earlier blog post.
- Higher overall SR quality and speed, thanks to new in-frame upsizing
method.
- More precise control on SR quality/speed trade-off (4 modes and a slider
to choose between quality and speed).
- Unicode, multilanguage support, easy to add translations (just add a text
file).
- Can work with lower than normal priority - doesn't slow down other
applications even with 100% CPU load.
- Fixed conflict with nVidia drivers that caused problems in Vista and
Windows 7 when Aero was turned on (only on nVidia cards).
- Now you can easily save and load projects (sequences of filters with all
their settings). Just right click the filters box in Advanced mode.
- Some minor changes (like drag'n'dropping files to main window) and
bugfixes (e.g. placing output files in same folder in batch mode).
- Better Win7 compatibility: doesn't try to write to Program Files, uses
proper directories instead for storing its data (like list of filters).
tags: video_enhancer
Scene change detection
June 4, 2010
We're very close to releasing the next version of
Video Enhancer. Today we added a scene change
detection algorithm into RGB version of super resolution engine. This feature
solves an annoying problem of all previous versions of VE: when a scene changes
in the video, first frames of the new scene contain some noise resulted from
SR fusing current image with previous hi-def frame. Now VE detects a change
and starts processing the scene from scratch, as if it was another video.
Basically this means that first frame of new scene is upsized by interpolation
and later frames are processed with SR.
Here's an example. This is a first frame of a scene:

VE 1.9.3, no scenes detection
|

VE 1.9.4, scenes detection on
|
In the left picture you can see the noise near a logo in upper-left corner
as well as around people's shoulders and heads.
In the right picture you can see this noise is gone.
tags: video_enhancer super_resolution
Older posts
| 
 RSS
RSS