|
The real problem with GC in D
September 29, 2014
About a year ago one blog post titled
"Why mobile web apps are slow"
made a lot of fuss in the internets. In the section about garbage collection it showed one
interesting chart taken from a 2005
paper
"Quantifying the Performance of Garbage Collection vs. Explicit Memory Management":
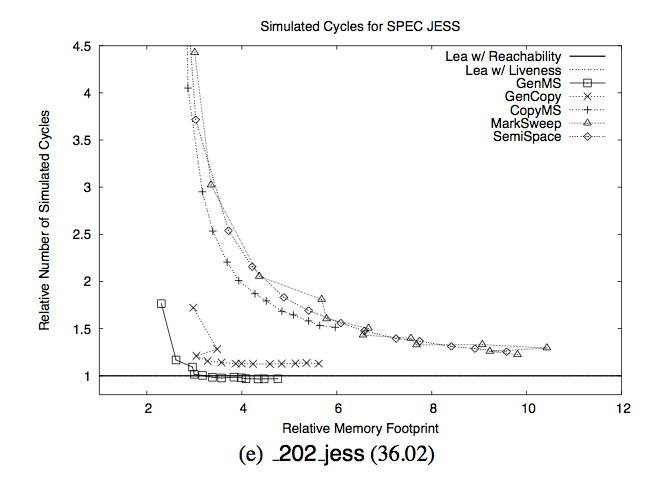
The intent was to frighten people and show how bad GCs were: they allegedly make your program super
slow unless you give them 5-8x more memory than strictly necessary. You may notice that the author has
chosen a chart for one particular program from the test set and you can rightfully guess that
most other programs didn't behave that bad and average case picture is much less frightening.
However what I immediately saw in this graph is something different and probably more important.
There are two very distinct groups of lines here: one where lines look like y=1/x equation and
reach sky high indeed and another one where the points are actually very close to the bottom left
corner (meaning "work fast and don't need too much memory")
and some of them even descend below the y=1 line, which means program with this kind of GC
worked faster than one with manual memory deallocation. The great gap between these two
groups of GC variants is the most important fact on this picture. And you know what is the main
difference between those 2 ways to implement GC? The group above ("shitty GCs that need a lot of
memory and are still slow") are non-generational GCs. The group below ("GCs that need much less
memory and work about as fast or even faster than malloc/free") are generational GCs.
By the way GCs in JVM, CLR and natively compiled functional languages like Haskell and OCaml are all
generational, so don't be fooled by this chart.
Moreover, those real-world GCs are much more advanced,
tuned and optimized than the toy implementations made by some students for an academic paper,
so it's reasonable to expect them on similar chart to be even lower and lefter, i.e. requiring less
memory and working faster.
So what is a generational garbage collector? First, let's recap how any tracing GC works. A running program
has a set of roots - pieces of memory where objects are certainly "live": mainly the stack,
global variables and regions of memory explicitly added to the set of roots. Root objects may have pointers
to other objects, those objects can have pointers to even more other objects, so the program can always
reach to these objects and use them.
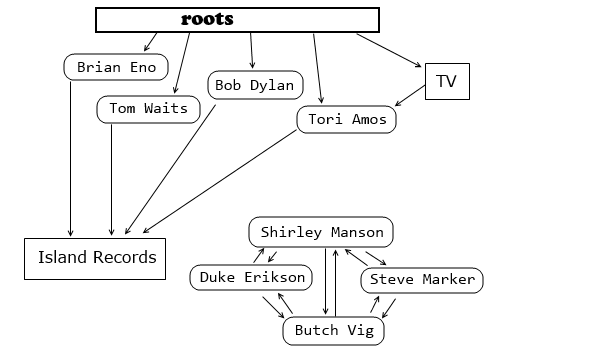
However if some object doesn't have any pointers to it from live, reachable objects anymore then it
cannot be used. Such objects, even if they point to each other, like Shirley Manson and her friends
in this example, are called Garbage.
Garbage collector
starts from the roots and walks the graph of objects following all the pointers they have.
During the walk it either marks visited objects as alive or copies them to their new home.
In the former case all unmarked objects (after graph walking is finished) are garbage and get
freed (by joining the free lists for example). In the latter case of copying GC the live objects
find themselves compactified in some memory region while the old space which they abandoned
now contains only garbage and so can be reused later as a clean space for newly allocated objects.
Of course, this graph walking process takes time, a lot of time. In D if you have 1 GB of small
objects in its GC-managed heap, one GC cycle may take a few seconds. Partly because determining
whether some word looks like a proper pointer to managed heap object is a costly operation in D
(as opposed to OCaml, for example, where just one bit of the word needs to be checked). Partly because
if an object contains some pointers the GC in D will scan all the words in this object, not just
the pointers, so more work than necessary gets done. Surely, these things can be improved and optimized,
and the whole process can be parallelized to some extent, however it won't make GC radically faster:
instead of several seconds per GB we might probably reach 1 second / GB, but hardly significantly
better, because no matter how fast your CPU operation is, thrashing cache by reading hundreds of megs
of data won't ever be fast, the RAM is too slow these days.
So what's the solution? Just don't go through the whole heap, only process a small part of it.
This is what generational GCs do. They employ the "generational hypothesis": most objects die young,
and those who don't die quickly tend to stick around for ages. So it makes sense to do GC among
the recently allocated objects first, this should free a lot of memory, and only if that's still
not enough then go for older objects.
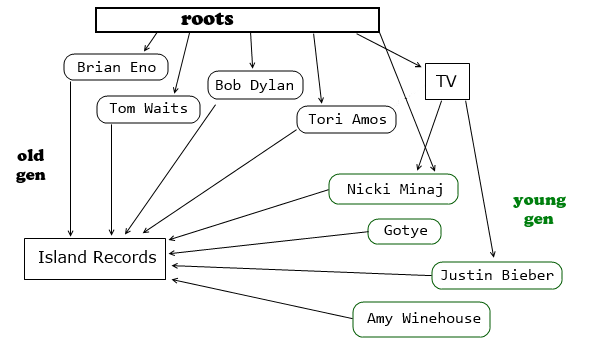
In this example objects allocated after last garbage collection belong to "young gen". Some of them
are already unreachable (even if they have pointers to live objects; to be live you need to be referenced
by a live object). So how do we garbage collect just the young generation? We start from roots
but don't walk through the old gen objects, that would lead to whole heap traversal which we want
to avoid. So from roots we follow pointers to the young gen and there follow pointers only to
young objects, we don't bother marking the old objects since we're not interested in collecting them at
this moment. But this way, in example above, we can only find one young live object: "Nicki". To find
another globally reachable young object "Justin" we need to know that it's referenced by some old gen
object "TV". We need to know about this pointer but we don't want to walk the whole graph to learn about
its existence. There are two known solutions to this problem. You can be a purely functional language
that forbids mutating objects, so that older objects just cannot point to younger ones, because
to create such a pointer you need to mutate the old object. No old-to-young pointers - no problem! This
is what Erlang does. Or, you can use write barriers on old objects and every time you change
some pointer inside an old object you check whether it's a pointer to the young gen, and if so you
either remember this pointer (add to "remembered set") or mark the whole page in the old gen
to scan it during next GC cycle. The latter is called "card marking". In our example, when the pointer
from "TV" to "Justin" is created it's either added to remembered set of pointers or the page containing
"TV" gets marked and during the young gen GC it's also scanned so that this pointer gets discovered.
This approach with scanning just the young generation most of the time is what makes industrial
GCs so fast. Some of them even have more than 2 generations so that you don't pause for seconds
when young gen collection wasn't enough.
If scanning/collecting 200 MBs of objects takes 1 second (as it does in D now),
then 200 KB can be scanned/collected in 1 ms. You want your GC to work just 1 ms? Either use
generational GC with 200 KB young gen, or keep your whole heap in 200 KB (good luck with that ;) ),
there's no real way around it.
And here we get to the problem with GC in D. To make fast GC it needs to be generational, but generational
GC means write barriers: you can't just freely mutate memory, every pointer mutation must be accompanied
by additional bookkeeping. Either the compiler inserts this bookkeeping code automatically in all the places
where your code mutates a pointer, or you use
virtual memory protection mechanisms to write-protect old gen pages and mark them when an exception caused
by an attempt to write there is triggered. Both ways are costly, they make the language not "as fast as C".
And being "fast as C" (or faster, if possible) is one of the things most D developers love so much.
So, I'm afraid, the community will be strongly against adding write barriers. And, since D is no Erlang,
without write barriers it's doomed to have non-generational GC. Which means its GC will always be
very slow (compated to other GCed languages).
My take away from this is that when writing in D you should only use GC for small litter, i.e. some
short-lived tiny objects, and for larger and longer living objects use deterministic memory management
tools available in the language and libraries.
tags: programming
| 
 RSS
RSS